Next: The Current State of Up: Main Reference Previous: New Features in 5.2.13 Contents Index
There are no new features in version 3.0.3. This version simply fixes a number of bugs found in version 3.0.2 during the ongoing development process.
This chapter presents the new features added to the Released Bacula Version 3.0.2.
This feature allows selecting a single JobId and having Bacula automatically select all the other jobs that comprise a full backup up to and including the selected date (through JobId).
Assume we start with the following jobs:
+-------+--------------+---------------------+-------+----------+------------+ | jobid | client | starttime | level | jobfiles | jobbytes | +-------+--------------+---------------------+-------+----------+------------ | 6 | localhost-fd | 2009-07-15 11:45:49 | I | 2 | 0 | | 5 | localhost-fd | 2009-07-15 11:45:45 | I | 15 | 44143 | | 3 | localhost-fd | 2009-07-15 11:45:38 | I | 1 | 10 | | 1 | localhost-fd | 2009-07-15 11:45:30 | F | 1527 | 44143073 | +-------+--------------+---------------------+-------+----------+------------+
Below is an example of this new feature (which is number 12 in the menu).
* restore
To select the JobIds, you have the following choices:
1: List last 20 Jobs run
2: List Jobs where a given File is saved
...
12: Select full restore to a specified Job date
13: Cancel
Select item: (1-13): 12
Enter JobId to get the state to restore: 5
Selecting jobs to build the Full state at 2009-07-15 11:45:45
You have selected the following JobIds: 1,3,5
Building directory tree for JobId(s) 1,3,5 ... +++++++++++++++++++
1,444 files inserted into the tree.
This project was funded by Bacula Systems.
A feature has been added which allows the administrator to specify the address from which the Director and File daemons will establish connections. This may be used to simplify system configuration overhead when working in complex networks utilizing multi-homing and policy-routing.
To accomplish this, two new configuration directives have been implemented:
FileDaemon {
FDSourceAddress=10.0.1.20 # Always initiate connections from this address
}
Director {
DirSourceAddress=10.0.1.10 # Always initiate connections from this address
}
Simply adding specific host routes on the OS would have an undesirable side-effect: any application trying to contact the destination host would be forced to use the more specific route possibly diverting management traffic onto a backup VLAN. Instead of adding host routes for each client connected to a multi-homed backup server (for example where there are management and backup VLANs), one can use the new directives to specify a specific source address at the application level.
Additionally, this allows the simplification and abstraction of firewall rules when dealing with a Hot-Standby director or storage daemon configuration. The Hot-standby pair may share a CARP address, which connections must be sourced from, while system services listen and act from the unique interface addresses.
This project was funded by Collaborative Fusion, Inc.
When doing a restore the selection dialog ends by displaying this screen:
The job will require the following
Volume(s) Storage(s) SD Device(s)
===========================================================================
*000741L3 LTO-4 LTO3
*000866L3 LTO-4 LTO3
*000765L3 LTO-4 LTO3
*000764L3 LTO-4 LTO3
*000756L3 LTO-4 LTO3
*001759L3 LTO-4 LTO3
*001763L3 LTO-4 LTO3
001762L3 LTO-4 LTO3
001767L3 LTO-4 LTO3
Volumes marked with ``*'' are online (in the autochanger).
This should help speed up large restores by minimizing the time spent waiting for the operator to discover that he must change tapes in the library.
This project was funded by Bacula Systems.
The estimate command can now use the accurate code to detect changes and give a better estimation.
You can set the accurate behavior on the command line by using accurate=yes|no or use the Job setting as default value.
* estimate listing accurate=yes level=incremental job=BackupJob
This project was funded by Bacula Systems.
This chapter presents the new features added to the development 2.5.x versions to be released as Bacula version 3.0.0 sometime in April 2009.
As with most other backup programs, by default Bacula decides what files to backup for Incremental and Differential backup by comparing the change (st_ctime) and modification (st_mtime) times of the file to the time the last backup completed. If one of those two times is later than the last backup time, then the file will be backed up. This does not, however, permit tracking what files have been deleted and will miss any file with an old time that may have been restored to or moved onto the client filesystem.
One note of caution about using Accurate backup is that it requires more resources (CPU and memory) on both the Director and the Client machines to create the list of previous files backed up, to send that list to the File daemon, for the File daemon to keep the list (possibly very big) in memory, and for the File daemon to do comparisons between every file in the FileSet and the list. In particular, if your client has lots of files (more than a few million), you will need lots of memory on the client machine.
Accurate must not be enabled when backing up with a plugin that is not specially designed to work with Accurate. If you enable it, your restores will probably not work correctly.
This project was funded by Bacula Systems.
A new Copy job type 'C' has been implemented. It is similar to the existing Migration feature with the exception that the Job that is copied is left unchanged. This essentially creates two identical copies of the same backup. However, the copy is treated as a copy rather than a backup job, and hence is not directly available for restore. The restore command lists copy jobs and allows selection of copies by using jobid= option. If the keyword copies is present on the command line, Bacula will display the list of all copies for selected jobs.
* restore copies [...] These JobIds have copies as follows: +-------+------------------------------------+-----------+------------------+ | JobId | Job | CopyJobId | MediaType | +-------+------------------------------------+-----------+------------------+ | 2 | CopyJobSave.2009-02-17_16.31.00.11 | 7 | DiskChangerMedia | +-------+------------------------------------+-----------+------------------+ +-------+-------+----------+----------+---------------------+------------------+ | JobId | Level | JobFiles | JobBytes | StartTime | VolumeName | +-------+-------+----------+----------+---------------------+------------------+ | 19 | F | 6274 | 76565018 | 2009-02-17 16:30:45 | ChangerVolume002 | | 2 | I | 1 | 5 | 2009-02-17 16:30:51 | FileVolume001 | +-------+-------+----------+----------+---------------------+------------------+ You have selected the following JobIds: 19,2 Building directory tree for JobId(s) 19,2 ... ++++++++++++++++++++++++++++++++++++++++++++ 5,611 files inserted into the tree. ...
The Copy Job runs without using the File daemon by copying the data from the old backup Volume to a different Volume in a different Pool. See the Migration documentation for additional details. For copy Jobs there is a new selection directive named PoolUncopiedJobs which selects all Jobs that were not already copied to another Pool.
As with Migration, the Client, Volume, Job, or SQL query, are other possible ways of selecting the Jobs to be copied. Selection types like SmallestVolume, OldestVolume, PoolOccupancy and PoolTime also work, but are probably more suited for Migration Jobs.
If Bacula finds a Copy of a job record that is purged (deleted) from the catalog, it will promote the Copy to a real backup job and will make it available for automatic restore. If more than one Copy is available, it will promote the copy with the smallest JobId.
A nice solution which can be built with the new Copy feature is often called disk-to-disk-to-tape backup (DTDTT). A sample config could look something like the one below:
Pool {
Name = FullBackupsVirtualPool
Pool Type = Backup
Purge Oldest Volume = Yes
Storage = vtl
NextPool = FullBackupsTapePool
}
Pool {
Name = FullBackupsTapePool
Pool Type = Backup
Recycle = Yes
AutoPrune = Yes
Volume Retention = 365 days
Storage = superloader
}
#
# Fake fileset for copy jobs
#
Fileset {
Name = None
Include {
Options {
signature = MD5
}
}
}
#
# Fake client for copy jobs
#
Client {
Name = None
Address = localhost
Password = "NoNe"
Catalog = MyCatalog
}
#
# Default template for a CopyDiskToTape Job
#
JobDefs {
Name = CopyDiskToTape
Type = Copy
Messages = StandardCopy
Client = None
FileSet = None
Selection Type = PoolUncopiedJobs
Maximum Concurrent Jobs = 10
SpoolData = No
Allow Duplicate Jobs = Yes
Cancel Queued Duplicates = No
Cancel Running Duplicates = No
Priority = 13
}
Schedule {
Name = DaySchedule7:00
Run = Level=Full daily at 7:00
}
Job {
Name = CopyDiskToTapeFullBackups
Enabled = Yes
Schedule = DaySchedule7:00
Pool = FullBackupsVirtualPool
JobDefs = CopyDiskToTape
}
The example above had 2 pool which are copied using the PoolUncopiedJobs selection criteria. Normal Full backups go to the Virtual pool and are copied to the Tape pool the next morning.
The command list copies [jobid=x,y,z] lists copies for a given jobid.
*list copies +-------+------------------------------------+-----------+------------------+ | JobId | Job | CopyJobId | MediaType | +-------+------------------------------------+-----------+------------------+ | 9 | CopyJobSave.2008-12-20_22.26.49.05 | 11 | DiskChangerMedia | +-------+------------------------------------+-----------+------------------+
Currently the following platforms support ACLs:
Currently we support the following ACL types (these ACL streams use a reserved part of the stream numbers):
In future versions we might support conversion functions from one type of acl into an other for types that are either the same or easily convertible. For now the streams are separate and restoring them on a platform that doesn't recognize them will give you a warning.
Currently the following platforms support extended attributes:
On Linux acls are also extended attributes, as such when you enable ACLs on a Linux platform it will NOT save the same data twice e.g. it will save the ACLs and not the same extended attribute.
To enable the backup of extended attributes please add the following to your fileset definition.
FileSet {
Name = "MyFileSet"
Include {
Options {
signature = MD5
xattrsupport = yes
}
File = ...
}
}
An important advantage of using shared objects is that on a machine with the Directory, File daemon, the Storage daemon, and a console, you will have only one copy of the code in memory rather than four copies. Also the total size of the binary release is smaller since the library code appears only once rather than once for every program that uses it; this results in significant reduction in the size of the binaries particularly for the utility tools.
In order for the system loader to find the shared objects when loading the Bacula binaries, the Bacula shared objects must either be in a shared object directory known to the loader (typically /usr/lib) or they must be in the directory that may be specified on the ./configure line using the -libdir option as:
./configure --libdir=/full-path/dir
the default is /usr/lib. If -libdir is specified, there should be no need to modify your loader configuration provided that the shared objects are installed in that directory (Bacula does this with the make install command). The shared objects that Bacula references are:
libbaccfg.so libbacfind.so libbacpy.so libbac.so
These files are symbolically linked to the real shared object file, which has a version number to permit running multiple versions of the libraries if desired (not normally the case).
If you have problems with libtool or you wish to use the old way of building static libraries, or you want to build a static version of Bacula you may disable libtool on the configure command line with:
./configure --disable-libtool
./configure --enable-static-client-only --disable-libtool
Bacula's virtual backup feature is often called Synthetic Backup or Consolidation in other backup products. It permits you to consolidate the previous Full backup plus the most recent Differential backup and any subsequent Incremental backups into a new Full backup. This new Full backup will then be considered as the most recent Full for any future Incremental or Differential backups. The VirtualFull backup is accomplished without contacting the client by reading the previous backup data and writing it to a volume in a different pool.
In some respects the Vbackup feature works similar to a Migration job, in that Bacula normally reads the data from the pool specified in the Job resource, and writes it to the Next Pool specified in the Job resource. Note, this means that usually the output from the Virtual Backup is written into a different pool from where your prior backups are saved. Doing it this way guarantees that you will not get a deadlock situation attempting to read and write to the same volume in the Storage daemon. If you then want to do subsequent backups, you may need to move the Virtual Full Volume back to your normal backup pool. Alternatively, you can set your Next Pool to point to the current pool. This will cause Bacula to read and write to Volumes in the current pool. In general, this will work, because Bacula will not allow reading and writing on the same Volume. In any case, once a VirtualFull has been created, and a restore is done involving the most current Full, it will read the Volume or Volumes by the VirtualFull regardless of in which Pool the Volume is found.
The Vbackup is enabled on a Job by Job in the Job resource by specifying a level of VirtualFull.
A typical Job resource definition might look like the following:
Job {
Name = "MyBackup"
Type = Backup
Client=localhost-fd
FileSet = "Full Set"
Storage = File
Messages = Standard
Pool = Default
SpoolData = yes
}
# Default pool definition
Pool {
Name = Default
Pool Type = Backup
Recycle = yes # Automatically recycle Volumes
AutoPrune = yes # Prune expired volumes
Volume Retention = 365d # one year
NextPool = Full
Storage = File
}
Pool {
Name = Full
Pool Type = Backup
Recycle = yes # Automatically recycle Volumes
AutoPrune = yes # Prune expired volumes
Volume Retention = 365d # one year
Storage = DiskChanger
}
# Definition of file storage device
Storage {
Name = File
Address = localhost
Password = "xxx"
Device = FileStorage
Media Type = File
Maximum Concurrent Jobs = 5
}
# Definition of DDS Virtual tape disk storage device
Storage {
Name = DiskChanger
Address = localhost # N.B. Use a fully qualified name here
Password = "yyy"
Device = DiskChanger
Media Type = DiskChangerMedia
Maximum Concurrent Jobs = 4
Autochanger = yes
}
Then in bconsole or via a Run schedule, you would run the job as:
run job=MyBackup level=Full run job=MyBackup level=Incremental run job=MyBackup level=Differential run job=MyBackup level=Incremental run job=MyBackup level=Incremental
So providing there were changes between each of those jobs, you would end up with a Full backup, a Differential, which includes the first Incremental backup, then two Incremental backups. All the above jobs would be written to the Default pool.
To consolidate those backups into a new Full backup, you would run the following:
run job=MyBackup level=VirtualFull
And it would produce a new Full backup without using the client, and the output would be written to the Full Pool which uses the Diskchanger Storage.
If the Virtual Full is run, and there are no prior Jobs, the Virtual Full will fail with an error.
Note, the Start and End time of the Virtual Full backup is set to the values for the last job included in the Virtual Full (in the above example, it is an Increment). This is so that if another incremental is done, which will be based on the Virtual Full, it will backup all files from the last Job included in the Virtual Full rather than from the time the Virtual Full was actually run.
Compared to the Win32 Bacula Client, the 64 bit release contains a few differences:
This project was funded by Bacula Systems.
The four directives each take as an argument a yes or no value and are specified in the Job resource.
They are:
If Allow Duplicate Jobs is set to no and two jobs are present and none of the three directives given below permit Canceling a job, then the current job (the second one started) will be canceled.
This new feature uses Bacula's existing TLS code (normally used for communications encryption) to do authentication. To use it, you must specify all the TLS directives normally used to enable communications encryption (TLS Enable, TLS Verify Peer, TLS Certificate, ...) and a new directive:
TLS Authenticate = yes
in the main daemon configuration resource (Director for the Director, Client for the File daemon, and Storage for the Storage daemon).
When TLS Authenticate is enabled, after doing the CRAM-MD5 authentication, Bacula will also do TLS authentication, then TLS encryption will be turned off, and the rest of the communication between the two Bacula daemons will be done without encryption.
If you want to encrypt communications data, use the normal TLS directives but do not turn on TLS Authenticate.
Honor No Dump Flag = yes|no
The default value is no.
# List of files to be backed up
FileSet {
Name = "MyFileSet"
Include {
Options {
signature = MD5
}
File = /home
Exclude Dir Containing = .excludeme
}
}
But in /home, there may be hundreds of directories of users and some people want to indicate that they don't want to have certain directories backed up. For example, with the above FileSet, if the user or sysadmin creates a file named .excludeme in specific directories, such as
/home/user/www/cache/.excludeme /home/user/temp/.excludeme
then Bacula will not backup the two directories named:
/home/user/www/cache /home/user/temp
NOTE: subdirectories will not be backed up. That is, the directive applies to the two directories in question and any children (be they files, directories, etc).
Plugins are also planned (partially implemented) in the Director and the Storage daemon.
Note: this directive may be specified, and there is code to modify the string in the run command, but the plugin options are not yet passed to the plugin (i.e. not fully implemented).
FileSet {
Name = "MyFileSet"
Include {
Options {
signature = MD5
}
File = /home
Plugin = "bpipe:..."
}
}
In the above example, when the File daemon is processing the directives in the Include section, it will first backup all the files in /home then it will load the plugin named bpipe (actually bpipe-dir.so) from the Plugin Directory. The syntax and semantics of the Plugin directive require the first part of the string up to the colon (:) to be the name of the plugin. Everything after the first colon is ignored by the File daemon but is passed to the plugin. Thus the plugin writer may define the meaning of the rest of the string as he wishes.
Please see the next section for information about the bpipe Bacula plugin.
The purpose of the plugin is to provide an interface to any system program for backup and restore. As specified above the bpipe plugin is specified in the Include section of your Job's FileSet resource. The full syntax of the plugin directive as interpreted by the bpipe plugin (each plugin is free to specify the sytax as it wishes) is:
Plugin = "<field1>:<field2>:<field3>:<field4>"
where
Please note that for two items above describing the "reader" and "writer" fields, these programs are "executed" by Bacula, which means there is no shell interpretation of any command line arguments you might use. If you want to use shell characters (redirection of input or output, ...), then we recommend that you put your command or commands in a shell script and execute the script. In addition if you backup a file with the reader program, when running the writer program during the restore, Bacula will not automatically create the path to the file. Either the path must exist, or you must explicitly do so with your command or in a shell script.
Putting it all together, the full plugin directive line might look like the following:
Plugin = "bpipe:/MYSQL/regress.sql:mysqldump -f
--opt --databases bacula:mysql"
The directive has been split into two lines, but within the bacula-dir.conf file would be written on a single line.
This causes the File daemon to call the bpipe plugin, which will write its data into the "pseudo" file /MYSQL/regress.sql by calling the program mysqldump -f -opt -database bacula to read the data during backup. The mysqldump command outputs all the data for the database named bacula, which will be read by the plugin and stored in the backup. During restore, the data that was backed up will be sent to the program specified in the last field, which in this case is mysql. When mysql is called, it will read the data sent to it by the plugn then write it back to the same database from which it came (bacula in this case).
The bpipe plugin is a generic pipe program, that simply transmits the data from a specified program to Bacula for backup, and then from Bacula to a specified program for restore.
By using different command lines to bpipe, you can backup any kind of data (ASCII or binary) depending on the program called.
Microsoft Exchange organises its storage into Storage Groups with Databases inside them. A default installation of Exchange will have a single Storage Group called 'First Storage Group', with two Databases inside it, "Mailbox Store (SERVER NAME)" and "Public Folder Store (SERVER NAME)", which hold user email and public folders respectively.
In the default configuration, Exchange logs everything that happens to log files, such that if you have a backup, and all the log files since, you can restore to the present time. Each Storage Group has its own set of log files and operates independently of any other Storage Groups. At the Storage Group level, the logging can be turned off by enabling a function called "Enable circular logging". At this time the Exchange plugin will not function if this option is enabled.
The plugin allows backing up of entire storage groups, and the restoring of entire storage groups or individual databases. Backing up and restoring at the individual mailbox or email item is not supported but can be simulated by use of the "Recovery" Storage Group (see below).
If the DLL can not be found automatically it will need to be copied into the Bacula installation directory (eg C:\Program Files\Bacula\bin). The Exchange API DLL is named esebcli2.dll and is found in C:\Program Files\Exchsrvr\bin on a default Exchange installation.
Additionally, you can suffix the 'Plugin =' directive with ":notrunconfull" which will tell the plugin not to truncate the Exchange database at the end of a full backup.
An Incremental or Differential backup will backup only the database logs for each Storage Group by inspecting the "modified date" on each physical log file. Because of the way the Exchange API works, the last logfile backed up on each backup will always be backed up by the next Incremental or Differential backup too. This adds 5MB to each Incremental or Differential backup size but otherwise does not cause any problems.
By default, a normal VSS fileset containing all the drive letters will also back up the Exchange databases using VSS. This will interfere with the plugin and Exchange's shared ideas of when the last full backup was done, and may also truncate log files incorrectly. It is important, therefore, that the Exchange database files be excluded from the backup, although the folders the files are in should be included, or they will have to be recreated manually if a bare metal restore is done.
FileSet {
Include {
File = C:/Program Files/Exchsrvr/mdbdata
Plugin = "exchange:..."
}
Exclude {
File = C:/Program Files/Exchsrvr/mdbdata/E00.chk
File = C:/Program Files/Exchsrvr/mdbdata/E00.log
File = C:/Program Files/Exchsrvr/mdbdata/E000000F.log
File = C:/Program Files/Exchsrvr/mdbdata/E0000010.log
File = C:/Program Files/Exchsrvr/mdbdata/E0000011.log
File = C:/Program Files/Exchsrvr/mdbdata/E00tmp.log
File = C:/Program Files/Exchsrvr/mdbdata/priv1.edb
}
}
The advantage of excluding the above files is that you can significantly reduce the size of your backup since all the important Exchange files will be properly saved by the Plugin.
\Program Files\Exchsrvr\mdbdata\*) as Exchange can get confused by stray log files lying around.
Microsoft Exchange allows the creation of an additional Storage Group called the Recovery Storage Group, which is used to restore an older copy of a database (e.g. before a mailbox was deleted) into without messing with the current live data. This is required as the Standard and Small Business Server versions of Exchange can not ordinarily have more than one Storage Group.
To create the Recovery Storage Group, drill down to the Server in Exchange System Manager, right click, and select "New -> Recovery Storage Group...". Accept or change the file locations and click OK. On the Recovery Storage Group, right click and select "Add Database to Recover..." and select the database you will be restoring.
Restore only the single database nominated as the database in the Recovery Storage Group. Exchange will redirect the restore to the Recovery Storage Group automatically. Then run the restore.
When doing a full backup, the Exchange database logs are truncated by Exchange as soon as the plugin has completed the backup. If the data never makes it to the backup medium (eg because of spooling) then the logs will still be truncated, but they will also not have been backed up. A solution to this is being worked on. You will have to schedule a new Full backup to ensure that your next backups will be usable.
The "Enable Circular Logging" option cannot be enabled or the plugin will fail.
Exchange insists that a successful Full backup must have taken place if an Incremental or Differential backup is desired, and the plugin will fail if this is not the case. If a restore is done, Exchange will require that a Full backup be done before an Incremental or Differential backup is done.
The plugin will most likely not work well if another backup application (eg NTBACKUP) is backing up the Exchange database, especially if the other backup application is truncating the log files.
The Exchange plugin has not been tested with the Accurate option, so we recommend either carefully testing or that you avoid this option for the current time.
The Exchange plugin is not called during processing the bconsole estimate command, and so anything that would be backed up by the plugin will not be added to the estimate total that is displayed.
The according to libdbi (http://libdbi.sourceforge.net/) project: libdbi implements a database-independent abstraction layer in C, similar to the DBI/DBD layer in Perl. Writing one generic set of code, programmers can leverage the power of multiple databases and multiple simultaneous database connections by using this framework.
Currently the libdbi driver in Bacula project only supports the same drivers natively coded in Bacula. However the libdbi project has support for many others database engines. You can view the list at http://libdbi-drivers.sourceforge.net/. In the future all those drivers can be supported by Bacula, however, they must be tested properly by the Bacula team.
Some of benefits of using libdbi are:
The following drivers have been tested:
In the future, we will test and approve to use others databases engines (proprietary or not) like DB2, Oracle, Microsoft SQL.
To compile Bacula to support libdbi we need to configure the code with the -with-dbi and -with-dbi-driver=[database] ./configure options, where [database] is the database engine to be used with Bacula (of course we can change the driver in file bacula-dir.conf, see below). We must configure the access port of the database engine with the option -with-db-port, because the libdbi framework doesn't know the default access port of each database.
The next phase is checking (or configuring) the bacula-dir.conf, example:
Catalog {
Name = MyCatalog
dbdriver = dbi:mysql; dbaddress = 127.0.0.1; dbport = 3306
dbname = regress; user = regress; password = ""
}
The parameter dbdriver indicates that we will use the driver dbi with a mysql database. Currently the drivers supported by Bacula are: postgresql, mysql, sqlite, sqlite3; these are the names that may be added to string "dbi:".
The following limitations apply when Bacula is set to use the libdbi framework: - Not tested on the Win32 platform - A little performance is lost if comparing with native database driver. The reason is bound with the database driver provided by libdbi and the simple fact that one more layer of code was added.
It is important to remember, when compiling Bacula with libdbi, the following packages are needed:
You can download them and compile them on your system or install the packages from your OS distribution.
The status slots storage=storage-name command displays autochanger content.
Slot | Volume Name | Status | Media Type | Pool |
------+---------------+----------+-------------------+------------|
1 | 00001 | Append | DiskChangerMedia | Default |
2 | 00002 | Append | DiskChangerMedia | Default |
3*| 00003 | Append | DiskChangerMedia | Scratch |
4 | | | | |
If you an asterisk (*) appears after the slot number, you must run an update slots command to synchronize autochanger content with your catalog.
Note for the catalog to have Job Log entries, you must have a directive such as:
catalog = all
In your Director's Messages resource.
!$%&'()*+,-/:;<>?[]^`{|}~
This new behavior is indicated in the prompt if you read it carefully.
To replace it, a new bare metal recovery USB boot stick has been developed by Bacula Systems. This technology involves remastering a Ubuntu LiveCD to boot from a USB key.
Advantages:
The disadvantages are:
The documentation and the code can be found in the rescue package in the directory linux/usb.
Note that only higher priority jobs will start early. Suppose the director will allow two concurrent jobs, and that two jobs with priority 10 are running, with two more in the queue. If a job with priority 5 is added to the queue, it will be run as soon as one of the running jobs finishes. However, new priority 10 jobs will not be run until the priority 5 job has finished.
During a restore, if all File records are pruned from the catalog for a Job, normally Bacula can restore only all files saved. That is there is no way using the catalog to select individual files. With this new feature, Bacula will ask if you want to specify a Regex expression for extracting only a part of the full backup.
Building directory tree for JobId(s) 1,3 ... There were no files inserted into the tree, so file selection is not possible.Most likely your retention policy pruned the files Do you want to restore all the files? (yes|no): no Regexp matching files to restore? (empty to abort): /tmp/regress/(bin|tests)/ Bootstrap records written to /tmp/regress/working/zog4-dir.restore.1.bsr
The new code can also restore POSIX(UFS) ACLs to a ZFS filesystem (it will translate the POSIX(UFS)) ACL into a ZFS/NFSv4 one) it can also be used to transfer from UFS to ZFS filesystems.
The Bat communications protocol has been significantly enhanced to improve GUI handling. Note, you must use a the bat that is distributed with the Director you are using otherwise the communications protocol will not work.
Job {
Name = aJob
RunScript {
Command = "/bin/echo test"
Command = "/bin/echo an other test"
Command = "/bin/echo 3 commands in the same runscript"
RunsWhen = Before
}
...
}
A new Client RunScript RunsWhen keyword of AfterVSS has been implemented, which runs the command after the Volume Shadow Copy has been made.
Console commands can be specified within a RunScript by using: Console = command, however, this command has not been carefully tested and debugged and is known to easily crash the Director. We would appreciate feedback. Due to the recursive nature of this command, we may remove it before the final release.
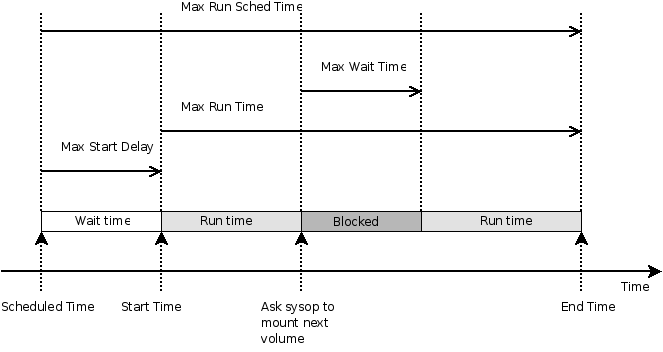
These directives have been deprecated in favor of Incremental|Differential Max Run Time.
However, these statistics are accurate only if your job retention is greater than your statistics period. Ie, if jobs are purged from the catalog, you won't be able to use them.
Now, you can use the update stats [days=num] console command to fill the JobHistory table with new Job records. If you want to be sure to take in account only good jobs, ie if one of your important job has failed but you have fixed the problem and restarted it on time, you probably want to delete the first bad job record and keep only the successful one. For that simply let your staff do the job, and update JobHistory table after two or three days depending on your organization using the [days=num] option.
These statistics records aren't used for restoring, but mainly for capacity planning, billings, etc.
The Bweb interface provides a statistics module that can use this feature. You can also use tools like Talend or extract information by yourself.
The Statistics Retention = time director directive defines the length of time that Bacula will keep statistics job records in the Catalog database after the Job End time. (In JobHistory table) When this time period expires, and if user runs prune stats command, Bacula will prune (remove) Job records that are older than the specified period.
You can use the following Job resource in your nightly BackupCatalog job to maintain statistics.
Job {
Name = BackupCatalog
...
RunScript {
Console = "update stats days=3"
Console = "prune stats yes"
RunsWhen = After
RunsOnClient = no
}
}
A new -B option allows you to print catalog information in a simple text based format. This is useful to backup it in a secure way.
$ dbcheck -B catalog=MyCatalog db_type=SQLite db_name=regress db_driver= db_user=regress db_password= db_address= db_port=0 db_socket=
You can now specify the database connection port in the command line.
Kern Sibbald 2015-07-04